
[2024-12-09] AI 오픈소스 트렌드 리뷰
Exaone 3.5 출시와 텍스트 모델 대세 조짐

안녕하세요, 솔론입니다.
텍스트 모델들이 다시 트렌드에 많이 보이고 있습니다.
지금 보니까 멀티모달 모델들이 많아지는 시기와 텍스트 모델들이 많아지는 시기가 번갈아 가면서 오는 것 같습니다.
instruct 키워드는 Image-Text-to-Text 모델을 포함하여 7개로, 가장 높은 빈도수를 보였습니다.
여기에는 새로 트렌드에 등장한 LGAI-EXAONE/EXAONE-3.5-32B-Instruct과 다시 트렌드로 돌아온 Llama-3.1-Nemotron-70B-Instruct-HF를 포함합니다.

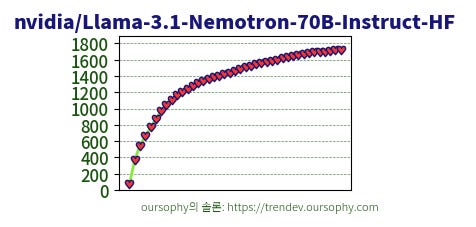
Llama-3.1-Nemotron-70B-Instruct-HF의 경우 오랜만에 트렌드에 돌아왔습니다.
이쯤 되면 Nemotron 70B는 텍스트 대세의 상징으로 봐도 되지 않을까도 싶습니다.
Nemotron 70B는 nvida가 Llama-3.1을 파인튜닝하여 공개한 오픈소스 LLM으로, 크기 대비 높은 성능으로 오랫동안 주목을 받았던 모델입니다.
LG에서 LGAI-EXAONE/EXAONE-3.5-32B-Instruct를 공개했습니다.
LG는 대략 4달 전쯤에 LGAI-EXAONE/EXAONE-3.0-7.8B-Instruct를 공개해서 준수한 성능에 주목을 받았으나 라이선스가 너무 까다로워 비판을 받았던 모델입니다.
그 이후 좀 더 관대하게 라이선스가 변경됐으나 여전히 비상업적입니다.
이번에 공개된 EXAONE-3.5-32B-Instruct의 경우에도 동일하게 exaone 라이선스를 가지고 있으므로 상업적 이용은 금지돼 있습니다.
다만 3.0를 공개하던 당시 7.8B 단일 모델만 공개했던 것과 달리 이번에는 2.4B, 7.8B, 32B 모델 시리즈를 공개했습니다.
이번에 트렌드에 올라온 것은 이 중 32B 모델이며, 공식적으로 한국어와 영어를 지원합니다.

그럼 이제 오늘 [2024-12-09]의 트렌드 변화를 확인해보겠습니다.
자세한 내용들은 TrenDevSophy에서 확인해주세요.
----새로 등장한 트렌드----
Datou1111/shou_xin:
본 모델은 '手訫(shou xin)' 작가의 연필 스케치 스타일을 재현한 모델입니다.
이미지 생성 시에는 `shou_xin, pencil sketch` 키워드를 사용하는 것이 좋습니다.
ComfyUI 워크플로우는 제공 링크(https://openart.ai/workflows/datou/pencil-sketch/jNotO6649m9OxqVzJeBx)에서 확인 가능합니다.
모델 가중치는 Safetensors 형식으로 제공되며, 파일 및 버전 탭에서 다운로드할 수 있습니다.
지난 달 다운로드 횟수는 47회입니다.
onnx-community/dpt-dinov2-small-kitti:
Hugging Face에서 제공하는 onnx-community/dpt-dinov2-small-kitti 모델은 Depth Estimation에 사용됩니다.
Transformers.js와 호환되도록 ONNX 가중치를 사용합니다.
현재 WebML의 활용도가 낮아 ONNX 가중치를 위한 별도 저장소를 임시로 사용하고 있습니다.
모델을 웹에서 사용하려면 🤗 Optimum을 사용하여 ONNX로 변환하고, ONNX 가중치를 onnx라는 하위 폴더에 저장하는 것이 좋습니다.
Inference API (서버리스)는 아직 이 파이프라인 유형의 transformers.js 모델을 지원하지 않습니다.
LGAI-EXAONE/EXAONE-3.5-32B-Instruct:
LG AI 연구소에서 개발한 EXAONE 3.5는 영어와 한국어를 지원하는 2.4B, 7.8B, 32B 매개변수의 다양한 크기의 양방향 생성 모델을 포함하는 모델 시리즈입니다.
32B 모델은 최대 32,768 토큰의 긴 문맥 처리를 지원하며, 실제 사용 사례와 긴 문맥 이해에서 최첨단 성능을 보여줍니다.
본 저장소는 지시 사항에 따라 미세 조정된 32B 언어 모델을 포함하며, 매개변수 수(임베딩 제외)는 30.95B, 계층 수는 64, 어텐션 헤드 수는 GQA(40개의 Q-헤드와 8개의 KV-헤드)입니다.
모델은 개인 정보, 유해 정보 또는 기타 부적절한 정보가 포함된 부적절한 응답을 생성할 수 있으며, 편향된 응답을 생성할 수도 있습니다. 또한 최신 정보를 반영하지 않아 잘못되거나 모순되는 응답을 생성할 수 있습니다.
EXAONE 모델은 EXAONE AI 모델 라이선스 계약 1.1 - NC에 따라 라이선스가 부여됩니다.
OpenGVLab/InternVL2_5-78B:
InternVL 2.5-78B는 InternVL 2.0을 기반으로 한 고급 다중 모드 대규모 언어 모델(MLLM) 시리즈입니다.
기존 모델 아키텍처를 유지하면서 훈련 및 테스트 전략과 데이터 품질을 크게 향상시켰습니다.
InternViT-6B-448px-V2_5와 Qwen2.5-72B-Instruct 모델을 통합하여 구성되었습니다.
다양한 다중 모드 및 언어 기능 평가를 거쳤습니다.
MIT 라이선스와 Qwen 라이선스 하에 배포됩니다.
nvidia/Llama-3.1-Nemotron-70B-Instruct-HF:
NVIDIA에서 개발한 Llama-3.1-Nemotron-70B-Instruct-HF는 사용자 질문에 대한 응답의 유용성을 높이도록 개선된 대규모 언어 모델입니다.
Arena Hard, AlpacaEval 2 LC, GPT-4-Turbo MT-Bench 등 여러 벤치마크에서 최고 성능을 기록했습니다.
RLHF(강화 학습) 기반으로 훈련되었으며, Hugging Face Transformers 라이브러리를 통해 사용할 수 있습니다.
최대 128,000개의 토큰을 입력으로 받아 최대 4,000개의 토큰을 출력합니다.
NVIDIA Ampere, Hopper, Turing 아키텍처와 Linux 운영 체제를 지원합니다.
google/paligemma2-3b-pt-224:
PaliGemma 2는 이미지와 텍스트를 입력으로 받아 텍스트를 출력하는 다국어 지원 비전-언어 모델입니다.
Gemma 2 언어 모델과 SigLIP 비전 모델을 기반으로 PaLI-3 레시피를 따라 학습되었습니다.
이미지 캡션 생성, 시각적 질문 응답, 객체 탐지 및 분할 등 다양한 비전-언어 작업에 사용될 수 있습니다.
TPUv5e 하드웨어와 JAX, Flax, TFDS, big_vision 소프트웨어를 사용하여 학습되었습니다.
다양한 벤치마크에서 우수한 성능을 보였으나, 편향성, 허위 정보 생성 가능성 등의 한계점이 존재합니다.
toloka/u-math:
Hugging Face에서 제공하는 U-MATH는 대학 수준의 수학 문제 1,100개로 구성된 종합적인 벤치마크입니다.
다양한 수학 분야(미적분, 다변수 미적분 등)를 다루며, 그래프나 도표 등 시각 자료를 포함하는 다중 모달 문제도 20% 포함되어 있습니다.
LLM(대규모 언어 모델)의 수학적 추론 능력 평가를 위해 설계되었으며, 정확도를 포함한 다양한 평가 지표를 제공합니다.
데이터셋은 MIT 라이선스로 이용 가능하며, 연구에 사용 시 논문을 인용해야 합니다.
문제는 대학 강의 자료에서 발췌되었으며, Toloka AI와 Gradarius의 수학 전문가들이 검증했습니다.
----인사이트 확인하기----
일간 인사이트:
트렌드 변화 분석을 통한 현재 업계 동향 인사이트:
과거 트렌드는 대규모 언어 모델(LLM)과 이미지 생성 모델의 성능 향상에 초점이 맞춰져 있었습니다. 특히, 파라미터 수 증가를 통한 성능 개선이 주된 방향이었으며, 다국어 지원 및 특정 분야(코딩, 이미지 생성)에 특화된 모델들이 등장했습니다. 오픈소스 모델의 공개 또한 활발하게 이루어졌으나, 모델의 크기와 자원 소모량이 상당하여 접근성에 제한이 있었습니다. 데이터셋 또한 LLM과 이미지 생성 모델 학습에 필요한 대규모 데이터 확보에 중점을 두었습니다.
최근 트렌드는 모델의 효율성 및 접근성 향상, 다양한 모달리티 통합, 특정 분야에 대한 세분화된 모델 개발, 데이터셋의 품질 개선 및 다양화로 변화하고 있습니다. 과거 대규모 파라미터 모델 중심에서 벗어나, LoRA와 같은 경량화 기술을 활용하여 자원 소모량을 줄이고 접근성을 높이는 모델들이 주목받고 있습니다. 또한, 비디오 생성 모델, 3D 모델 생성 모델 등 다양한 모달리티를 통합하는 모델들이 등장하여, 멀티모달 AI 기술의 발전을 가속화하고 있습니다. 데이터셋 측면에서는, 특정 작업(예: 이미지 편집, 코드 생성)에 특화된 고품질 데이터셋 개발이 활발하며, 다국어 지원 및 편향성 최소화 노력이 강화되고 있습니다.
미래 예측:
향후 AI 업계는 다음과 같은 방향으로 발전할 것으로 예상됩니다.
* 초경량 모델의 발전: 모바일 및 에지 디바이스에서도 고성능 AI 서비스를 제공하기 위한 초경량 모델 개발이 가속화될 것입니다. LoRA와 같은 기술이 더욱 발전하고, 모델 압축 기술과의 결합을 통해 더욱 효율적인 모델이 등장할 것으로 예상됩니다.
* 멀티모달 AI의 심화: 텍스트, 이미지, 비디오, 오디오 등 다양한 모달리티를 자연스럽게 통합하고 이해하는 AI 기술이 더욱 발전하여, 실제 세계와의 상호작용이 더욱 자연스러워질 것입니다. 특히, 비전-언어 모델의 발전은 UI 자동화, 로보틱스 등 다양한 분야에 혁신을 가져올 것으로 예상됩니다.
* 특화된 모델의 증가: 특정 분야(의료, 법률, 교육 등)에 특화된 전문적인 AI 모델들이 더욱 많이 개발될 것입니다. 이러한 전문 모델들은 해당 분야의 전문가들이 더욱 효율적으로 업무를 수행할 수 있도록 지원하는 역할을 할 것입니다.
* 데이터 품질 관리의 중요성 증대: AI 모델의 성능은 학습 데이터의 품질에 크게 의존합니다. 향후, 데이터셋의 품질 관리 및 편향성 제거에 대한 노력이 더욱 강화될 것이며, 데이터셋의 신뢰성 및 투명성 확보가 중요한 과제가 될 것입니다.
* 오픈소스 생태계의 확장: 오픈소스 모델과 데이터셋의 공유는 AI 기술 발전에 중요한 역할을 합니다. 향후, 오픈소스 생태계가 더욱 확장될 것이며, 커뮤니티 기반의 협력을 통해 더욱 빠르고 효율적인 AI 기술 발전이 이루어질 것으로 예상됩니다.
현재 업계 동향 요약:
현재 AI 업계는 모델 경량화, 멀티모달 통합, 그리고 특정 분야에 대한 전문화라는 세 가지 주요 트렌드를 중심으로 발전하고 있습니다. 이러한 트렌드는 AI 기술의 접근성을 높이고, 실제 세계 문제 해결에 대한 AI의 활용 가능성을 더욱 확대할 것으로 예상됩니다.
주간 인사이트:
과거 트렌드 분석: 저번 주와 이번 주 트렌드를 비교 분석한 결과, 대규모 언어 모델(LLM)과 이미지 생성 모델의 발전이 두드러졌습니다. 특히, Qwen, FLUX, Stable Diffusion 등 오픈소스 모델의 업데이트와 새로운 모델의 등장이 눈에 띄었습니다. 추론 능력 향상에 초점을 맞춘 QwQ-32B-Preview와 다중 모드 이미지 생성 모델인 Qwen2vl-Flux, 그리고 실시간 고품질 비디오 생성 모델인 LTX-Video 등이 주목할 만한 사례입니다. 또한, Bluesky Social 데이터셋과 같은 소셜 미디어 데이터 활용의 증가도 확인되었습니다. 반면, 일부 애플리케이션은 CPU 업그레이드 중이거나 페이지 정보 갱신 중인 등의 이슈를 보였습니다.
최신 트렌드 분석: 최신 트렌드는 과거 트렌드와 유사하게 LLM과 이미지/비디오 생성 모델의 발전에 집중되어 있습니다. 그러나, 최신 트렌드에서는 모델의 규모와 성능이 더욱 향상되었고, 특히 비디오 생성 모델의 발전이 괄목할 만합니다. Tencent의 HunyuanVideo와 같은 고품질 비디오 생성 모델의 등장은 향후 비디오 생성 분야의 급격한 발전을 예측하게 합니다. 또한, 다국어 지원 및 다중 모달 모델(이미지, 텍스트, 오디오 등을 처리하는 모델)의 발전이 가속화되고 있으며, 이는 향후 AI 애플리케이션의 다양성과 활용도를 높일 것으로 예상됩니다. 특히, Meta의 Llama 3.3-70B-Instruct 모델은 다국어 대화 능력 향상에 큰 발전을 이루었고, ShowUI와 같은 경량의 비전-언어-액션 모델은 온디바이스 애플리케이션 개발을 가속화할 것으로 예상됩니다.
현재 업계 동향 인사이트: 현재 AI 업계는 LLM과 생성 모델의 경쟁이 심화되고 있으며, 오픈소스 모델의 활약이 두드러집니다. 모델의 성능 향상과 더불어 다국어 지원, 다중 모달 기능, 추론 능력 향상 등이 중요한 경쟁력으로 부상하고 있습니다. 비디오 생성 분야는 빠른 발전 속도를 보이고 있으며, 향후 더욱 고품질의 비디오 콘텐츠를 쉽게 생성하는 기술이 등장할 것으로 예상됩니다. 소셜 미디어 데이터를 활용한 연구도 활발히 진행되고 있으며, 이는 소셜 미디어 분석 및 예측 모델 개발 등 다양한 분야에 적용될 것으로 예상됩니다. 모델의 효율성 또한 중요한 요소로 부각되고 있으며, 경량화된 모델과 효율적인 훈련 기법 개발이 업계의 주요 과제 중 하나입니다.
미래 예측: 향후 AI 업계는 더욱 강력하고 효율적인 LLM과 생성 모델의 등장이 예상됩니다. 다중 모달 기능이 더욱 발전하여, 이미지, 비디오, 오디오, 텍스트 등 다양한 모달리티를 통합적으로 처리하는 모델이 주류를 이룰 것으로 예상됩니다. 개인 맞춤형 AI 서비스와 실시간 상호 작용이 가능한 AI 애플리케이션이 더욱 확산될 것으로 예상되며, 이를 위해서는 모델의 경량화와 에지 컴퓨팅 기술의 발전이 중요한 역할을 할 것입니다. 또한, 데이터의 윤리적 사용과 모델의 안전성에 대한 관심이 더욱 높아질 것이며, 책임감 있는 AI 개발과 배포가 업계의 중요한 화두가 될 것으로 예상됩니다.
월간 인사이트:
텐센트의 Hunyuan 모델 계열의 약진과 오픈소스 생태계 확장: 텐센트는 Hunyuan-Large 모델에서 한 단계 더 나아가 HunyuanVideo 모델을 출시하며 비디오 생성 분야에서도 경쟁력을 확보했습니다. 이는 텍스트 및 이미지 생성 모델의 발전에 이어 비디오 생성 분야까지 오픈소스 생태계가 확장되고 있음을 시사합니다. 과거 텍스트 기반 모델 중심에서 멀티모달 모델로의 전환이 가속화되고 있으며, 향후 멀티모달 모델의 발전과 오픈소스화가 더욱 활발해질 것으로 예상됩니다.
메타의 Llama 모델 시리즈의 지속적인 업데이트와 상용화 가능성: Llama 시리즈는 Llama-3.1에서 Llama-3.3까지 지속적으로 업데이트되고 있으며, 특히 Llama-3.3-70B-Instruct는 다국어 대화에 최적화되어 상용화 가능성을 높였습니다. 이는 대규모 언어 모델의 상용화 경쟁이 치열해지고 있으며, 오픈소스 모델과 상용 모델 간의 경계가 모호해지고 있음을 의미합니다. 향후에는 오픈소스 모델의 상용화가 더욱 활발해질 것으로 예상되며, 이에 따라 오픈소스 모델의 라이선스 및 상용화 조건이 더욱 중요해질 것입니다.
다양한 모달리티를 지원하는 통합 모델의 등장: 과거에는 텍스트, 이미지, 음성 등 각 모달리티별로 전문화된 모델이 주로 사용되었지만, 최근에는 HunyuanVideo나 Llama-3.2-11B-Vision-Instruct와 같이 여러 모달리티를 통합적으로 처리하는 모델이 등장하고 있습니다. 이는 모델의 활용성을 높이고, 다양한 응용 분야에 적용 가능하도록 만듭니다. 향후에는 더욱 다양한 모달리티를 통합하는 모델이 등장할 것으로 예상되며, 이를 통해 인공지능 기술이 더욱 현실 세계와 밀접하게 연결될 것입니다.
효율성 향상을 위한 경량화 모델의 발전: SmolLM2, MobileLLM-1B와 같이 기존 대규모 모델에 비해 크기가 작고, 효율적인 경량화 모델이 등장하고 있습니다. 이는 모바일 기기나 자원 제약이 있는 환경에서도 인공지능 기술을 활용할 수 있도록 합니다. 향후에는 더욱 경량화되고, 성능이 향상된 모델이 개발될 것으로 예상되며, 이를 통해 인공지능 기술의 접근성이 더욱 높아질 것입니다.
LoRA를 활용한 모델 미세조정의 확산: FLUX.1-dev를 비롯한 여러 모델에서 LoRA를 활용한 미세조정이 활발하게 이루어지고 있습니다. 이는 특정 분야에 특화된 모델을 효율적으로 개발할 수 있도록 하며, 모델 개발의 진입장벽을 낮춥니다. 향후에는 더욱 다양한 모델에 LoRA가 적용될 것으로 예상되며, 이를 통해 사용자 맞춤형 모델 개발이 더욱 활성화될 것입니다.
오픈소스 데이터셋의 증가와 다양화: 다양한 분야(수학, 코드, 이미지, 음성 등)를 아우르는 방대한 양의 오픈소스 데이터셋이 지속적으로 공개되고 있습니다. 이는 오픈소스 모델 개발을 촉진하고, 모델의 성능 향상에 기여합니다. 향후에는 더욱 고품질의 데이터셋이 공개될 것으로 예상되며, 이를 통해 인공지능 모델의 성능이 더욱 향상될 것입니다. 데이터셋의 품질 관리 및 저작권 문제 해결이 중요한 과제가 될 것입니다.
특정 분야에 특화된 모델의 등장: TableGPT2-7B (테이블 데이터 분석), Fish Agent (환경 오디오 생성), OmniParser (UI 스크린샷 분석) 등 특정 분야에 특화된 모델이 등장하고 있습니다. 이는 인공지능 기술이 특정 분야의 문제 해결에 더욱 효과적으로 적용될 수 있도록 합니다. 향후에는 더욱 다양한 분야에 특화된 모델이 개발될 것으로 예상되며, 이를 통해 인공지능 기술의 전문성이 더욱 강화될 것입니다.
합성 데이터 활용의 증가: Synth-APIGen-v0.1, BAAI/Infinity-MM 등 합성 데이터를 활용한 데이터셋이 증가하고 있습니다. 이는 실제 데이터 확보의 어려움을 해결하고, 데이터의 다양성을 확보하는 데 기여합니다. 향후에는 더욱 정교하고 현실적인 합성 데이터 생성 기술이 개발될 것으로 예상되며, 이를 통해 인공지능 모델 학습에 필요한 데이터 확보 문제가 더욱 완화될 것입니다.
실시간 상호작용 모델의 발전: Mini-Omni2, gpt-omni/mini-omni2 와 같이 실시간으로 사용자와 상호작용하는 모델이 등장하고 있습니다. 이는 인공지능 기술이 사용자 경험을 향상시키는 데 기여합니다. 향후에는 더욱 자연스럽고 효율적인 실시간 상호작용 모델이 개발될 것으로 예상되며, 이를 통해 인공지능 기술이 일상생활에 더욱 깊숙이 통합될 것입니다.
분기 인사이트:
과거 트렌드 대비 최신 트렌드 변화: 과거 트렌드는 주로 개별 모델의 성능 향상에 초점을 맞춘 반면, 최신 트렌드는 멀티모달(Multimodal) 및 다국어(Multilingual) 지원 강화, 그리고 효율성(Efficiency) 개선에 무게를 두고 있습니다. 과거에는 특정 작업(예: 이미지 생성, 코드 생성)에 특화된 모델이 주를 이루었지만, 최근에는 여러 작업을 처리할 수 있는 범용 모델, 혹은 특정 작업에 특화된 모델을 더욱 효율적으로 만드는 기법(예: LoRA)이 주목받고 있습니다. 더불어, 대규모 데이터셋의 중요성이 증대되고 있으며, 그 양과 질적 수준이 급격히 향상되었습니다.
업계 동향 분석 인사이트: LLM(Large Language Model) 분야는 성능 향상과 함께 다양한 모달리티와 언어를 지원하는 방향으로 진화하고 있습니다. 이는 텍스트뿐 아니라 이미지, 비디오, 오디오 등 다양한 데이터를 처리하고, 여러 언어를 이해하고 생성하는 모델의 수요 증가를 반영합니다. 또한, 모델의 크기보다는 성능 대비 효율성에 대한 관심이 높아지고 있으며, 이는 LoRA, 양자화(Quantization) 등의 경량화 기술 발전으로 이어지고 있습니다. 이는 클라우드 기반 서비스뿐 아니라, 모바일 기기와 같은 제한된 자원 환경에서도 LLM을 활용할 수 있는 가능성을 열어줍니다.
미래 예측: 미래에는 더욱 경량화되고 효율적인 멀티모달 LLM이 주류를 이룰 것으로 예상됩니다. 이는 다양한 기기에서 LLM을 활용할 수 있는 기반을 마련하고, 사용자 경험을 더욱 풍부하게 만들 것입니다. 또한, 개인 맞춤형 LLM의 중요성이 커질 것으로 예상되며, 이는 사용자의 특정 요구사항에 맞춰 모델을 미세 조정하는 기술의 발전과 더불어 사용자 데이터를 활용한 개인화된 서비스 제공이 확대될 것임을 시사합니다. 데이터셋의 질적 향상과 더불어 데이터 관리 및 윤리적 문제에 대한 관심도 더욱 높아질 것으로 예상됩니다.
경쟁 심화: 오픈소스 모델과 상용 모델 간의 경쟁이 더욱 심화될 것으로 예상됩니다. 오픈소스 모델은 접근성과 커뮤니티 참여를 기반으로 빠르게 발전하고 있으며, 상용 모델은 성능과 안정성을 강조하며 시장을 선점하려 할 것입니다. 이러한 경쟁은 LLM 기술의 발전을 가속화하고, 사용자에게 더 나은 서비스를 제공하는 데 기여할 것으로 예상됩니다.
기술적 난제: LLM의 확장성, 환각(Hallucination) 문제, 편향(Bias) 문제 등은 여전히 해결해야 할 중요한 기술적 과제입니다. 이러한 문제 해결을 위한 연구가 지속적으로 진행될 것이며, 이를 통해 LLM의 신뢰성과 안전성이 향상될 것으로 예상됩니다.
산업적 파급 효과: LLM 기술 발전은 다양한 산업 분야에 혁신적인 변화를 가져올 것으로 예상됩니다. 자동 번역, 챗봇, 콘텐츠 생성, 코딩 지원 등의 분야에서 LLM이 널리 활용될 것이며, 새로운 서비스와 비즈니스 모델이 등장할 것으로 예상됩니다. 하지만, 일자리 변화, 저작권 문제, 윤리적 문제 등에 대한 사회적 논의와 대비가 필요합니다.
특징 분석: 최신 트렌드에서는 비디오 생성 모델의 등장과 발전이 눈에 띕니다. 이는 텍스트와 이미지를 넘어 비디오 생성 분야까지 LLM의 적용 범위가 확장되고 있음을 보여줍니다. 또한, ControlNet과 같은 이미지 생성 모델의 제어 기능 향상을 위한 기술이 발전하고 있으며, 이는 사용자가 원하는 이미지를 더욱 정확하게 생성할 수 있도록 지원합니다. 마지막으로, LLM 기반 에이전트 개발 또한 활발하게 이루어지고 있으며, 이는 사용자의 다양한 요구사항을 처리하고, 복잡한 작업을 수행할 수 있는 지능형 시스템 개발에 대한 관심 증가를 반영합니다.