
[2024-12-17] AI 오픈소스 트렌드 리뷰
shou xin의 스케치 lora와 google의 최신 임베딩 모델 자랑

안녕하세요, 솔론입니다.
====<번외>
드디어 이번 글로 100번째 포스트가 됩니다.
내일부터는 사전에 얘기드린대로 “원래의 목적”인 비정기 뉴스래터로 돌아갑니다.
그러면 더 재밌는 순간마다 뵐 수 있도록 하겠습니다.
====</번외>
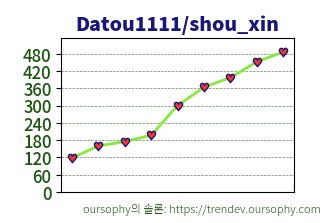
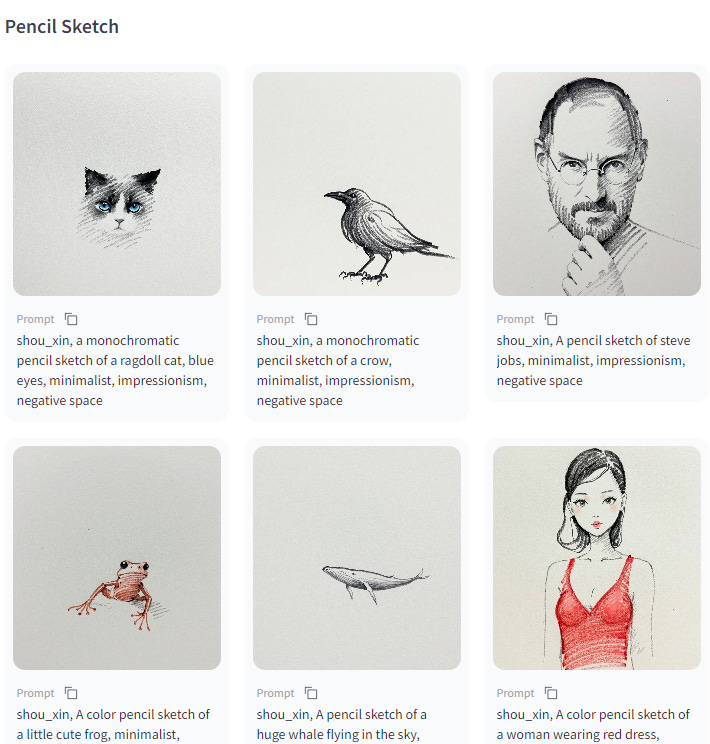
이미지 모델 중 flux-dev의 lora중 하나인 Datou1111/shou_xin가 높은 인기도를 유지하면서 트렌드 2위를 유지중입니다.
shou xin이라는 사람의 연필 스케치를 학습한 모델로, ‘shou_xin, pencil sketch’를 트리거로 사용합니다.
원본 작가는 중국의 현대 미술가라고 합니다.
특정인의 lora가 이렇게 오랫동안 상위권에 머무는 것은 특이한 일입니다.
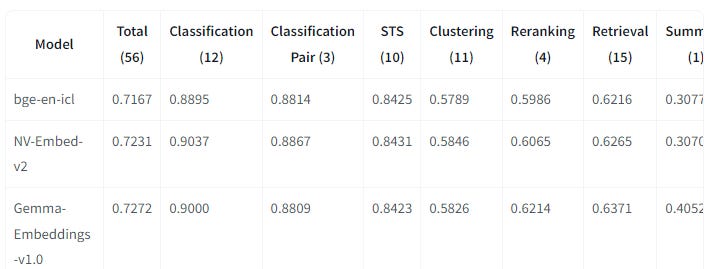
구글의 최근 오픈소스 임베딩 모델인 google/Gemma-Embeddings-v1.0가 트렌드에 올라왔습니다.
공식 google 제품이 아닌 연구 프로젝트라고 하며 정확한 임베딩 파일은 공개되지 않은 것으로 보입니다.
기본 인코딩 모델은 Gemma2 9B로, 임베딩 모델치고는 굉장히 큰 편에 속합니다.
임베딩 모델들도 크면 성적이 잘 나오는 경우가 많은데, 이정도면 라지 임베딩 모델 분야가 따로 있어도 되지 않나 싶긴 합니다.
그럼 이제 오늘 [2024-12-17]의 트렌드 변화를 확인해보겠습니다.
자세한 내용들은 TrenDevSophy에서 확인해주세요.
----새로 등장한 트렌드----
IamCreateAI/Ruyi-Mini-7B:
Ruyi-Mini-7B는 오픈소스 이미지 투 비디오 생성 모델입니다.
입력 이미지를 기반으로 360p~720p 해상도의 비디오 프레임을 최대 5초까지 생성합니다.
모션 및 카메라 제어 기능을 지원하여 유연하고 창의적인 비디오 생성이 가능합니다.
약 71억 개의 파라미터를 가지며, Apache 2.0 라이선스로 배포됩니다.
GitHub에서 코드를 설치하고 Python 코드 또는 ComfyUI 래퍼를 사용하여 실행할 수 있습니다.
Apollo-LMMs/Apollo-7B-t32:
Apollo는 비디오 이해를 위한 최첨단 대규모 다중 모드 모델(LMM)입니다.
장시간 비디오 이해, 시간적 추론, 복잡한 질의응답, 비디오 내용 기반의 다회차 대화 등의 작업을 지원합니다.
7B 매개변수 모델 변형으로, 3B 매개변수만으로도 대부분의 7B 경쟁 모델을 능가하며, 심지어 30B 규모의 모델과도 경쟁합니다.
프레임당 32토큰을 사용하며, 빠른 속도와 정확성을 균형 있게 유지합니다.
설치는 `pip install -e .` 및 `pip install flash-attn --no-build-isolation` 명령어를 사용합니다.
Infinigence/Megrez-3B-Omni:
Megrez-3B-Omni는 Infinigence AI에서 개발한 최초의 온디바이스 전모달 이해 오픈소스 모델입니다. 이미지, 텍스트, 오디오 세 가지 모달 데이터를 이해하고 분석하며, 각 분야에서 최고의 정확도를 달성했습니다.
이미지 이해 측면에서는 OpenCompass 벤치마크에서 평균 66.2점을 기록, LLaVA-NeXT-Yi-34B 등 대규모 모델을 능가했습니다. MME, MMMU, OCRBench 등에서도 최고 수준의 정확도를 보입니다.
텍스트 처리 능력 또한 뛰어나며, 단일 모달 버전(Megrez-3B-Instruct) 대비 정확도 저하는 2% 미만입니다. C-EVAL, MMLU/MMLU Pro, AlignBench 등에서 최고 성능을 유지합니다.
Qwen2-Audio/whisper-large-v3 인코더를 사용하여 중국어와 영어 음성 입력 및 멀티턴 대화를 지원하며, 이미지에 대한 음성 질문에도 텍스트로 응답합니다.
총 40억 개의 매개변수를 가지며, NVIDIA H100 환경에서 빠른 속도를 제공합니다.
google/Gemma-Embeddings-v1.0:
Gemma Embeddings v1.0는 검색에 특화된 고밀도 벡터 임베딩 모델입니다.
2024년 12월 12일 기준 MTEB 리더보드에서 종합 1위(72.72점)를 달성했습니다.
기반 모델은 Gemma2 9B이며, BGE-EN-ICL 학습 데이터를 사용했습니다.
구글의 공식 제품이 아니며, 연구 프로젝트임을 알려드립니다.
Nicholas Monath 등 여러 연구원이 개발에 참여했습니다.
FanLu31/CompreCap:
CompreCap 데이터셋은 사람이 주석을 단 장면 그래프를 특징으로 하며, 포괄적인 이미지 캡션 생성의 평가에 중점을 둡니다.
이미지 내 일반적인 객체에 대한 새로운 의미론적 분할 주석을 제공하며, 평균 마스크 적용 범위는 95.83%입니다.
객체의 세심한 주석 외에도 객체에 바인딩된 속성에 대한 고품질 설명과 객체 간의 방향 관계 설명을 포함하여 완전하고 방향이 지정된 장면 그래프 구조를 구성합니다.
분할 마스크, 범주 이름, 속성 및 관계 설명에 대한 주석은 ./anno.json에 저장됩니다.
CompreCap 벤치마크를 기반으로 연구자는 대규모 비전-언어 모델이 생성한 이미지 캡션의 품질에 포괄적으로 접근할 수 있습니다.
nkp37/OpenVid-1M:
OpenVid-1M은 텍스트-비디오 생성을 위한 대규모 고품질 데이터셋입니다.
고품질의 영상(최소 512x512 해상도)을 제공하며, 직접 학습 또는 다른 데이터셋의 보완용으로 사용 가능합니다.
1080p 영상 433,000개로 구성된 OpenVidHD도 함께 제공합니다.
데이터셋은 CC-BY-4.0 라이선스로 공개되며, `OpenVid-1M.csv` 및 `OpenVidHD.csv` 파일에는 텍스트-비디오 쌍이 포함되어 있습니다.
프로젝트 및 코드는 각각 [https://nju-pcalab.github.io/projects/openvid](https://nju-pcalab.github.io/projects/openvid) 와 [https://github.com/NJU-PCALab/OpenVid](https://github.com/NJU-PCALab/OpenVid) 에서 확인할 수 있습니다.
----인사이트 확인하기----
일간 인사이트:
트렌드 변화 분석: 과거 트렌드는 주로 대규모 언어 모델(LLM)과 이미지 생성 모델에 집중되어 있었으나, 최신 트렌드는 비디오 생성, 3D 모델 생성, 오디오 생성, 그리고 다중 모달 모델(Vision-Language Model) 등으로 확장되었습니다. 특히, 다양한 모달리티를 통합하는 모델과 효율적인 추론을 위한 최적화된 모델들이 주목받고 있습니다.
LLM의 발전: 과거에는 70B 파라미터의 LLM이 최첨단이었지만, 현재는 훨씬 더 큰 모델들(예: 78B 파라미터)이 등장하고 있으며, 코드 생성에 특화된 모델이나, 다국어 지원 및 다양한 작업에 최적화된 모델들이 개발되고 있습니다. 또한, 메모리 효율을 높이기 위한 양자화 기술이 활용되고 있습니다.
다중 모달 모델의 부상: 과거에는 LLM과 이미지 생성 모델이 주로 개별적으로 발전했지만, 최근에는 비전-언어 모델(Vision-Language Model)과 같은 다중 모달 모델이 급격히 발전하고 있습니다. 이러한 모델들은 이미지와 텍스트를 동시에 처리하여 더욱 풍부하고 복잡한 작업을 수행할 수 있습니다. 비디오 생성 모델 또한 텍스트나 이미지를 입력으로 받아 비디오를 생성하는 방향으로 발전하고 있습니다.
효율성 및 접근성 향상: 최신 트렌드에서는 모델의 크기가 커지는 것과 동시에, 효율적인 추론을 위한 기술(예: 양자화, 최적화된 아키텍처)이 발전하고 있습니다. 또한, 모델의 접근성을 높이기 위한 노력(예: 오픈소스 모델 공개, API 제공)이 활발하게 이루어지고 있습니다.
데이터셋의 다양화: 과거에는 영어 중심의 데이터셋이 많았지만, 최신 트렌드에서는 다국어를 지원하는 데이터셋과 다양한 모달리티(텍스트, 이미지, 비디오, 오디오)를 포함하는 데이터셋이 증가하고 있습니다. 특히, 특정 분야(코드, 수학, 법률 등)에 특화된 데이터셋들이 개발되고 있습니다.
오픈소스 모델의 확산: 과거에는 상용 모델이 주류였지만, 최근에는 오픈소스 모델의 비중이 크게 증가하고 있으며, 이는 연구 및 개발의 활성화에 기여하고 있습니다. 하지만, 오픈소스 모델의 라이선스 및 사용 제약에 대한 주의가 필요합니다.
업계 동향 예측: 향후에는 다중 모달 모델의 발전과 함께, 모델의 크기와 복잡성이 더욱 증가할 것으로 예상됩니다. 동시에, 더욱 효율적이고, 사용하기 쉽고, 윤리적인 모델 개발에 대한 요구가 증가할 것으로 예상됩니다. 또한, 개별 모델보다는 다양한 모델을 통합하는 시스템의 중요성이 커질 것으로 보입니다.
기술적 난제: 대규모 모델의 훈련 및 배포에 필요한 막대한 컴퓨팅 자원과 에너지 소비는 지속적인 과제로 남아 있으며, 모델의 편향성 및 안전성 확보를 위한 기술적 해결책이 요구됩니다.
상업적 활용: 오픈소스 모델의 증가는 상업적 활용의 문턱을 낮추지만, 라이선스 제약과 윤리적 문제에 대한 고려가 필수적입니다. 특히, 개인정보보호 및 저작권 문제는 상업적 활용 시 주의해야 할 중요한 사항입니다.
커뮤니티의 역할: 오픈소스 모델과 데이터셋의 발전에는 커뮤니티의 기여가 중요하며, 활발한 커뮤니티 참여와 협력을 통한 모델 개선 및 새로운 응용 분야 발굴이 기대됩니다.
규제 및 윤리: AI 모델의 발전과 함께, 모델의 편향성, 안전성, 저작권, 개인정보보호 등에 대한 규제 및 윤리적 고려가 더욱 중요해지고 있습니다. 업계는 이러한 문제에 대한 책임감 있는 접근 방식을 모색해야 합니다.
지속가능성: 대규모 모델 훈련에 필요한 에너지 소비를 줄이기 위한 친환경적인 기술 개발 및 에너지 효율적인 모델 아키텍처 연구가 중요해지고 있습니다.
주간 인사이트:
Llama 모델 계열의 상승세가 두드러집니다. 특히 메타의 Llama-3.3-70B-Instruct 모델은 다국어 지원과 뛰어난 성능으로 주목받고 있으며, 이전 버전들에 비해 8비트 및 4비트 양자화 지원으로 메모리 효율성이 향상되었습니다. 이는 오픈소스 모델의 성능 경쟁이 더욱 치열해지고 있음을 시사합니다.
텐센트의 HunyuanVideo와 같이 대규모 매개변수를 가진 오픈소스 비디오 생성 모델의 등장은 비디오 생성 분야의 기술 발전을 가속화하고 있습니다. 이는 향후 비디오 콘텐츠 제작 방식의 변화와 새로운 시장 창출을 예상하게 합니다.
이미지 생성 모델 분야에서는 FLUX 모델 계열의 인기가 지속되고 있으며, 특정 스타일(한국 경복궁, 롤스로이스 자동차, 연필 스케치 등)을 생성하는 LoRA 모델들이 다양하게 등장하여 사용자 맞춤형 이미지 생성이 가능해지고 있습니다. 이는 이미지 생성 기술이 더욱 세분화되고 대중화되고 있음을 보여줍니다.
다양한 언어 모델 학습용 데이터셋(FineWeb-2, Global-MMLU 등)의 등장은 다국어 지원 및 다양한 작업 수행 능력을 갖춘 언어 모델 개발을 위한 기반을 강화하고 있습니다. 이는 다국어 지원 및 다양한 작업 수행 능력을 갖춘 언어 모델 개발 경쟁 심화를 의미합니다.
코드 특화 대규모 언어 모델(Qwen2.5-Coder-32B-Instruct 등)의 발전은 AI 기반 소프트웨어 개발 및 자동화의 가능성을 확대하고 있습니다. 이는 향후 소프트웨어 개발 방식의 혁신 및 생산성 향상을 기대하게 합니다.
3D 모델 생성 및 이미지-3D 모델 변환 기술(TRELLIS 등)의 발전은 메타버스, 게임, 디자인 등 다양한 분야에 새로운 가능성을 제시하고 있습니다. 이는 향후 3D 콘텐츠 제작 및 활용의 증가와 관련 산업의 성장을 예상하게 합니다.
다양한 모달리티(텍스트, 이미지, 오디오, 비디오)를 통합하는 다중 모달 모델(ShowUI-2B, InternVL2_5-78B, Djrango/Qwen2vl-Flux 등)의 발전은 AI의 활용 범위를 더욱 넓히고 있습니다. 이는 향후 AI 기술의 융합과 새로운 응용 분야의 등장을 예상하게 합니다.
자동 음성 인식 및 음성 번역 기술(Whisper large-v3-turbo)의 발전은 언어 장벽을 허물고 다양한 언어 간의 소통을 원활하게 하는 데 기여하고 있습니다. 이는 향후 글로벌 커뮤니케이션 및 정보 접근성 향상에 기여할 것으로 예상됩니다.
오픈소스 모델과 폐쇄형 모델 간의 성능 격차가 줄어들고 있으며, 오픈소스 모델의 성능이 빠르게 향상되고 있습니다. 이는 AI 기술의 민주화 및 더욱 활발한 연구 개발 생태계 조성을 의미합니다.
데이터셋의 규모와 품질이 향상되고 있으며, 다양한 언어와 작업에 특화된 데이터셋들이 공개되고 있습니다. 이는 AI 모델의 성능 향상 및 새로운 응용 분야 발굴에 중요한 역할을 할 것으로 예상됩니다.
Hugging Face를 중심으로 오픈소스 AI 모델 및 데이터셋 생태계가 활성화되고 있으며, 이는 AI 기술 발전에 크게 기여하고 있습니다. 이는 향후 오픈소스 AI 생태계의 지속적인 성장과 확장을 예상하게 합니다.
LLM의 추론 능력 향상에 대한 연구가 활발히 진행되고 있으며, 단계별 추론 과정의 투명성과 제어성을 높이는 기술들이 개발되고 있습니다. 이는 AI의 신뢰성 향상과 책임 있는 AI 개발에 기여할 것으로 예상됩니다.
월간 인사이트:
트렌드 순위 변화 분석을 통한 업계 동향 인사이트: 저번 달과 이번 달 트렌드 순위 변화를 분석하여 코드 생성 모델(Qwen 시리즈, FLUX 시리즈 등)의 지속적인 상승세와 멀티모달 모델(Omnivision, Llama 시리즈 등)의 확장, 그리고 비디오 생성 모델(HunyuanVideo, Mochi 등)의 부상을 확인할 수 있습니다. 이는 AI 모델의 전문화와 다양한 모달리티 지원이 주요 트렌드임을 시사합니다. 반면, 일부 데이터셋(예: 특정 프롬프트 모음)은 순위 변동이 크지 않아, 해당 분야의 성숙도를 보여줍니다.
새로운 모델 등장 및 기술 발전: 최신 트렌드에서 Qwen 2.5 시리즈, Llama 3.3 시리즈, HunyuanVideo, DeepSeek-VL2 등 새로운 대규모 언어 모델 및 멀티모달 모델의 등장은 업계의 기술적 진보와 경쟁 심화를 보여줍니다. 특히, 긴 컨텍스트 처리 능력 향상과 다양한 양자화 기법의 적용은 모델의 효율성과 접근성을 높이는 중요한 발전입니다.
오픈소스 모델의 활성화 및 생태계 확장: Alibaba Cloud의 Qwen 시리즈, Meta의 Llama 시리즈, NVIDIA의 Llama-3.1-Nemotron 등 주요 기업들이 오픈소스 모델을 적극적으로 공개하고 있으며, 이는 오픈소스 AI 생태계의 확장과 활성화를 의미합니다. Hugging Face를 중심으로 한 모델 공유와 커뮤니티 활동은 이러한 트렌드를 더욱 가속화하고 있습니다.
전문화된 모델의 등장: 코드 전문 모델(Qwen-Coder 시리즈, OpenCoder 등)과 이미지 생성 모델(FLUX 시리즈, Stable Diffusion 시리즈 등), 비디오 생성 모델, 음성 합성 모델 등 특정 작업에 최적화된 전문화된 모델들이 증가하고 있습니다. 이는 AI 모델의 응용 분야가 다양화되고 있으며, 각 분야별 전문성이 중요해짐을 나타냅니다.
멀티모달 모델의 확장: 이미지와 텍스트를 결합한 멀티모달 모델의 성장은 AI 모델의 능력을 더욱 확장하고 있습니다. 이미지 생성, 이미지 캡션 생성, 시각적 질문 응답 등 다양한 작업에 활용되고 있으며, 향후 더욱 복잡한 멀티모달 작업을 처리할 수 있을 것으로 예상됩니다.
데이터셋의 양적 및 질적 향상: 대규모 고품질 데이터셋(PD12M, BLIP3-KALE 등)의 등장과 기존 데이터셋의 지속적인 업데이트는 AI 모델의 성능 향상에 중요한 역할을 합니다. 데이터셋의 전문화 (의료 영상, 법률 판례 등) 또한 특정 분야의 AI 모델 개발을 가속화하고 있습니다.
효율성 및 접근성 향상: 모델 크기의 다양화 (7B, 32B 등)와 양자화 기법의 적용은 다양한 하드웨어 환경에서 AI 모델을 효율적으로 실행할 수 있도록 합니다. 이는 AI 기술의 접근성을 높이고, 더욱 폭넓은 사용을 가능하게 합니다.
라이선스 정책의 다양화: 오픈소스 모델의 라이선스 정책은 상업적 사용 허용 여부, 비상업적 사용 제한 등 다양하게 나타납니다. 이는 AI 모델의 사용과 배포에 대한 주의가 필요하며, 라이선스 조건을 꼼꼼히 확인해야 함을 의미합니다.
실시간 처리 및 효율적인 추론: 실시간 이미지 및 비디오 생성 모델의 발전은 AI 기술의 실시간 응용 가능성을 높이고 있습니다. 또한, vLLM 등 효율적인 추론 기술의 발전은 모델의 성능을 유지하면서 리소스 사용량을 줄이는 데 기여하고 있습니다.
업계 경쟁 심화 및 협력: 주요 기업들의 오픈소스 모델 공개와 Hugging Face를 중심으로 한 활발한 커뮤니티 활동은 업계 경쟁 심화와 동시에 협력적인 생태계 구축을 보여줍니다. 이러한 경쟁과 협력은 AI 기술 발전을 더욱 가속화할 것으로 예상됩니다.
미래 예측: 앞으로는 더욱 전문화되고, 다양한 모달리티를 지원하며, 높은 효율성과 접근성을 갖춘 AI 모델들이 더욱 많이 등장할 것으로 예상됩니다. 오픈소스 생태계의 성장과 데이터셋의 질적 향상은 이러한 발전을 뒷받침할 것입니다. 또한, 윤리적 고려사항과 안전성 확보는 AI 기술 발전의 중요한 과제로 남을 것입니다.
현재 상황 요약: 현재 AI 업계는 모델의 전문화, 멀티모달 지원 확대, 오픈소스 생태계 확장, 효율성 및 접근성 향상이라는 주요 트렌드를 보이고 있습니다. 이러한 트렌드는 AI 기술의 다양한 분야로의 확장과 일상생활 깊숙한 곳까지의 침투를 가능하게 할 것입니다.
분기 인사이트:
과거 트렌드 대비 최신 트렌드 변화: 저번 분기와 이번 분기 트렌드 순위를 비교 분석한 결과, 대규모 언어 모델(LLM)과 이미지 생성 모델의 발전이 두드러지게 나타났습니다. 과거에는 특정 기능에 특화된 모델(예: 텍스트-음성 변환, HTML-Markdown 변환)이 주를 이루었다면, 최신 트렌드는 멀티모달 기능을 갖춘 대규모 모델(예: 이미지 이해 및 텍스트 생성, 비디오 생성)과 고품질 이미지 생성에 초점이 맞춰져 있습니다. 또한, 모델의 크기가 증가하고, 효율성을 높이기 위한 양자화 기술(예: GGUF)의 사용이 증가하고 있습니다. 데이터셋 또한 단일 모달에서 멀티모달로 확장되고 있으며, 더욱 정교한 데이터 생성 및 필터링 기법을 통해 고품질 데이터셋이 제공되고 있습니다.
LLM의 발전과 다중 모달: 이번 분기에는 70B 파라미터 이상의 대규모 LLM이 등장하여, 추론 능력, 코드 생성 능력, 다국어 지원 능력 등이 크게 향상되었습니다. 특히, 함수 호출 기능, 긴 컨텍스트 처리 기능 등이 강조되고 있으며, RAG(Retrieval Augmented Generation) 기술을 통한 정보 접근 및 활용이 더욱 중요해지고 있습니다. 또한, LLM과 이미지 생성 모델의 결합을 통해 멀티모달 기능을 갖춘 모델이 등장하여, 텍스트와 이미지를 동시에 처리하고 생성하는 것이 가능해졌습니다.
이미지 생성 모델의 고도화: 과거에는 텍스트를 기반으로 이미지를 생성하는 모델이 주류였다면, 최신 트렌드는 이미지의 품질, 세부 묘사, 스타일 제어 등이 크게 향상된 모델이 등장하고 있습니다. 특히, ControlNet과 같은 제어 메커니즘을 통해 이미지 생성 과정을 더욱 세밀하게 제어할 수 있게 되었으며, 고해상도 이미지 생성이 가능해졌습니다. 또한, 비디오 생성 모델의 등장으로, 텍스트나 이미지를 기반으로 고품질 비디오를 생성하는 것이 가능해졌습니다.
데이터셋의 질적 향상: 과거에는 데이터의 양이 중요한 요소였다면, 최신 트렌드는 데이터의 품질, 다양성, 정확성 등이 강조되고 있습니다. 특히, 저작권 문제 해결을 위해 공개 도메인 데이터나 CC0 라이선스 데이터를 사용하는 경향이 증가하고 있으며, 자동화된 데이터 정제 및 필터링 기법을 통해 오류나 편향을 최소화하려는 노력이 이루어지고 있습니다. 또한, 멀티모달 데이터셋이 등장하여, 이미지와 텍스트, 오디오 등 다양한 모달리티의 데이터를 통합적으로 활용하는 것이 가능해졌습니다.
효율성과 접근성: 최신 트렌드는 모델의 크기 증가에도 불구하고, 효율적인 추론을 위한 양자화 기법(예: GGUF, FP8)의 사용이 증가하고 있습니다. 이는 GPU 자원이 제한적인 사용자에게도 고성능 모델을 사용할 수 있도록 접근성을 높이는 데 기여합니다. 또한, 오픈소스 모델과 데이터셋의 증가는 개발자와 연구자들이 더욱 쉽게 최신 기술을 접하고 활용할 수 있도록 지원합니다.
업계 동향 인사이트: 멀티모달, 고품질, 고효율을 중심으로 한 기술 발전은 향후 AI 애플리케이션의 다양화와 실생활 적용 확대를 가속화할 것으로 예상됩니다. 특히, 비디오 생성, 가상 피팅, 실시간 음성 대화 등 새로운 애플리케이션 분야가 급격히 발전할 것으로 예측됩니다. 또한, 데이터 품질 관리 및 윤리적 문제에 대한 중요성이 더욱 커질 것으로 예상되며, 이에 대한 업계의 노력이 지속적으로 증가할 것으로 예상됩니다. 오픈소스 모델과 데이터셋의 활성화는 AI 기술의 민주화를 촉진하고 혁신을 가속화하는 데 기여할 것입니다.