
끝나지 않은 오픈소스, R1 신버전 출시
R1 새로운 버전 출시, 뛰어난 영상 오픈소스 wan, 꾸준히 올라오는 TTS

안녕하세요, 솔론입니다.
한 번 안 쓰기 시작하니 오랫동안 안쓰게 되네요 ㅎㅎㅎ;;; 오랜만에 돌아왔습니다…
전체적인 트렌드는 TrenDev를 확인해주세요
다시 돌아온 센세이션의 상징, R1
deepseek-ai에서 새로운 시리즈를 출시했습니다.
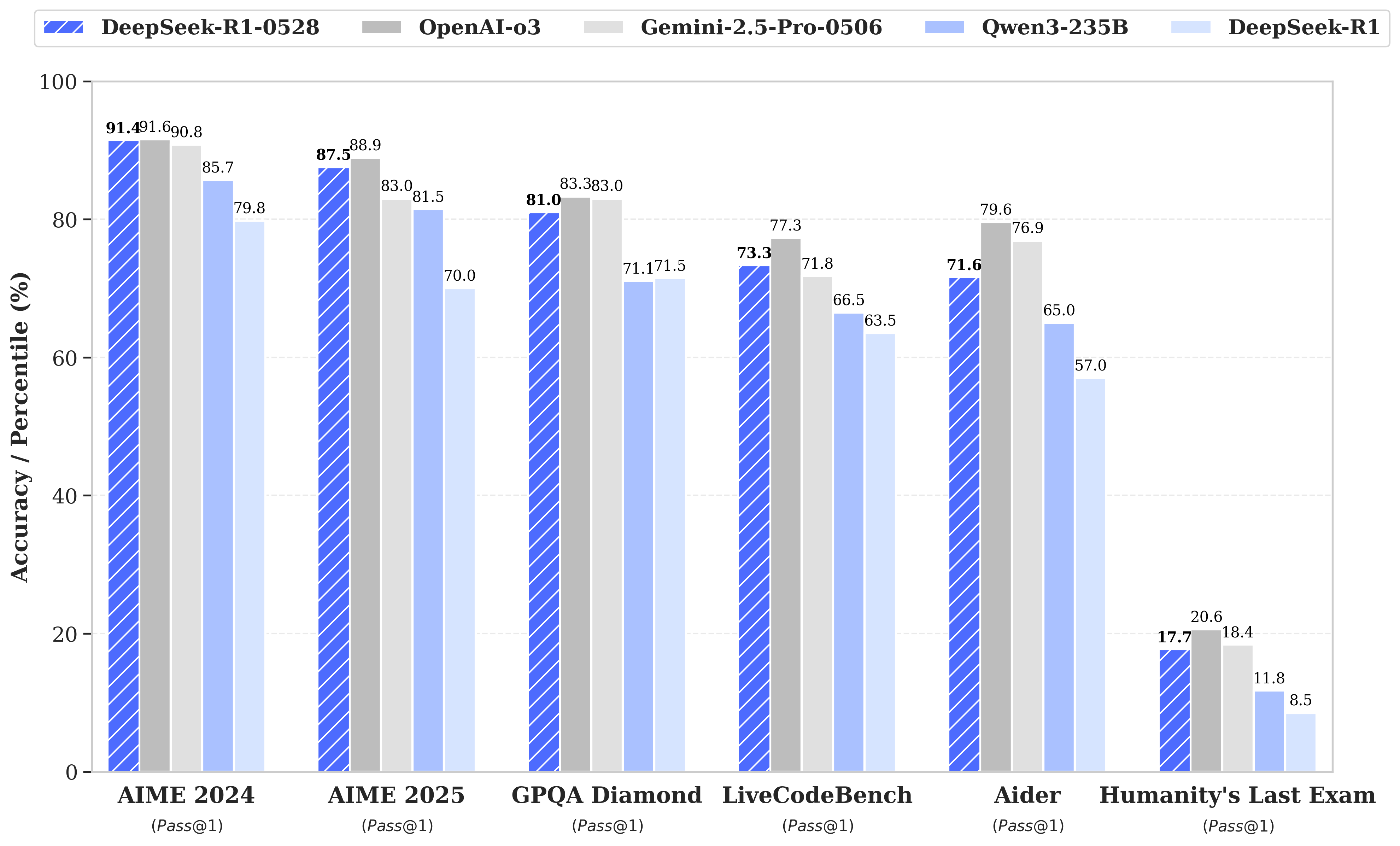
이전 버전 대비 추론 능력이 향상됐으며, 물론 추후의 리뷰들을 확인해야하지만 공식 벤치마크에서는 o3에 준하는 성적을 내고 있습니다.
현재 R1의 새로운 버전은 출시된지 하루도 채 된지 않았는데 허깅페이스 트렌드에서 1등으로 등극했습니다.
R1은 오픈소스 모델 중에서도 드물게도 비개발자 분들에게도 유명한 모델입니다. 2025년 2월쯤 출시된 deepseek R1은 다양한 유튜브는 물론이고 일반 뉴스에도 소개되는 등 다양한 매체를 통해 소개됐습니다.
어떠한 이미지로 기억하시는가는 각자마다 다르겠지만 가장 일반적으로는 중국에서 만든 고성능 인공지능, 좀 더 관심을 가지시는 분들은 부족한 GPU환경에서 만들어진 고효율 LLM, 주식을 하시는 분들은 nvidia 폭락의 주범 등등으로 기억하실 겁니다.
그만큼 R1의 등장은 중국 기술력이 충분히 미국을 따라갈 수 있다는 압박감과 더 효율적이면서도 저비용으로 언어모델 제작이 가능하리라는 기대감을 심어주기에 충분했습니다. 이후에 발표된 중국의 qwen사에서 발표한 qwen 시리즈 역시 오픈소스 중에서는 상당한 효율과 성능을 내면서 언어모델의 트렌드가 중국 모델 기반으로 덮이기도 했습니다.

이번에 새로 출시된 R1-0528이 그만큼 언론의 주목을 받을지는 미지수지만 일단 오픈소스 중에서는 최상급의 성능을 가진 것으로 보이고 있습니다. 이번 발표에 오픈소스의 발전과 커뮤니티의 성장 등 다양한 평가가 나올 수 있지만 개인적으로는 특히 아직 오픈소스 릴레이가 끝나지 않았다는 것에 의의를 두고 있습니다. 적어도 당분간은 오픈소스LLM이 이어질 것이며, 더 가성비이면서 고성능 모델이 나올 수 있으리라 생각합니다. (모델 링크: https://huggingface.co/deepseek-ai/DeepSeek-R1-0528)
동시에 출시한 R1-0528의 증류모델인 DeepSeek-R1-0528-Qwen3-8B의 경우 평가가 좋은 Qwen3-8B를 기반한 모델로, Qwen3-235B-thinking와 동등한 성능을 보인다고 주장하고 있습니다. (모델 링크: https://huggingface.co/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B)
점점 치열해지는 영상 생성, 중심의 wan
최근 구글에서 veo3로 영상생성 쪽도 점점 주목을 받고 있습니다.
그 이전에는 openAI의 sora모델이 한창 분위기를 달궜으나, 출시까지 너무 오래 지연됐으며 공개 성능도 기대치에 미치지 못하여 크게 주목받지 못하였죠.
그러다가 올해 3월쯤에는 모델을 업그레이드하면서 상당한 일관성 유지와 성능으로 충격을 주면서 “지브리” 화풍을 유행시키기도 했습니다.
현재 veo3는 그 충격을 넘어서 ai와 직업의 관계를 현실적으로 고민하게 만드는 수준입니다. 상당히 디테일한 영상은 물론이고 영상생성과 동시에 상황에 맞는 음성 및 효과음까지 생성하는 것으로 알려져 있습니다.
다만, veo3를 사용하기위해서는 ultra 요금제를 구독해야하며, 대략 $250으로 상당히 사악한 가격을 가지고 있습니다.

상업용 모델에 비해 주목도도 낮고 파급력도 낮지만 오픈소스 영상 모델도 존재합니다.
stable-video-diffusion, LTX-Video, hunyuanvideo, stepvideo 등등 다양한 모델들이 등장했지만 그 중에서 가장 주목도가 높은 모델은 wan일 것입니다.
제가 wan을 가장 꼽는 이유는 간단합니다. 현재 wan 기반으로 파생된 모델 카드들이 가장 많기 때문입니다. 저는 주로 허깅페이스 트렌드에서 1~5페이지를 자주 둘러보는데, 비디오 관련모델(t2v, i2v) 중에서는 wan 기반 모델을 가장 자주 확인할 수 있었습니다.
실제로 간단하게 검색을 통해 모델 수를 확인하면, wan이 가장 많음을 확인할 수 있으며, wan에 대한 평가가 상당히 좋은 편에 해당합니다.
비디오 모델은 크게 2가지로 갈립니다. 텍스트를 기반으로 비디오를 만드는 t2v와 이미지를 기반으로 비디오를 만드는 i2v입니다. wan은 1.3B~14B 크기로 공유돼 있으며 T2V로 표시된 모델은 t2v, vace모델은 i2v로 분류돼 있습니다.

또한 공식 문서 상 T2V-1.3B는 8.19GB VRAM 정도만 필요하므로 일반 사용자도 현실적으로 사용가능한 수준이며, 주로 comfyUI라는 오픈소스 웹UI에서 사용 가능합니다. (comfyUI 공식 지원: https://comfyanonymous.github.io/ComfyUI_examples/wan/)
꾸준한 트렌드, TTS
TTS모델은 LLM은 물론이고 영상/이미지 생성모델보다 언급은 덜 되는 것처럼 보이지만 트렌드 상위권에 꾸준히 랭킹되는 카테고리입니다.
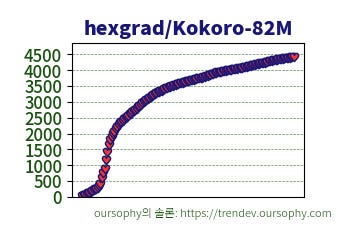
가벼움 대비 높은 성적을 거둔 kokoro-82M은 트렌드에서 거의 터줏대감 급으로 오래 버티고 있으며,
현재는 chatterbox라는 모델이 허깅페이스 모델 상위권(글을 쓰는 시점에서 6위)을 차지했습니다.

전체적인 모델들의 추세이긴 하지만, TTS 모델도 마찬가지인 특징이 점점 커지는 파라미터입니다. 특히 TTS모델들은 모델 크기가 커지면서 감정 표현 등 디테일한 기능들이 강화되고 있습니다.
감정 표현이 가능한 TTS는 기존에는 타입캐스트 등의 회사에서 개발한 일부 상업용 TTS 모델에서 가능하거나, 오픈소스 중에서는 극히 드물게 xTTS 등의 모델에서 구현하였습니다. 그러나 xTTS는 비상업 라이선스이며, 개발중단됐습니다.
그러나 최근에는 점점 감정 표현, 비언어적 표현이 가능한 TTS모델들이 더 자주 출시되고 있으며, 현재 트렌드에 새로 등장한 chatterbox와 한국인이 만든 것으로 유명한 dia-1.6b도 이에 해당합니다.

이번에 떠오르고 있는 chatterbox의 경우 MIT 라이선스로, 상업적 이용이 가능합니다. 또한 감정을 과장되게 표현하는 기능을 지원하는 최초의 오픈소스 TTS모델이라고 주장하고 있습니다. 다만 영어만 공식 지원하므로 한국어 등 다국어로 사용하셔야하는 분들께는 제한이 있을 수 있습니다.
허깅페이스 스페이스에서 테스트해볼 수 있으니 필요하신 분들은 접속해보시길 바랍니다. 주소: https://huggingface.co/spaces/ResembleAI/Chatterbox